How to Scrape Data from Websites using Google Sheets


Uncover the simplicity of web data scraping with Google Sheets in this article. While it may not match the complexity of Python scripts, it's user-friendly and might suit your needs.
Before we dive in, let's address the ethics of web scraping. Although not a major concern with Google Sheets, it's crucial to grasp potential issues, especially when considering advanced scraping in Python. A single error in the request variable could lead to a DDOS attack on a website.
Avoid scraping proprietary or copyrighted data, and steer clear of personally identifiable information like emails or phone numbers to comply with strict EU laws. Now, let's explore scraping methods – manual copying offers static data but becomes tedious for dynamic content updates. Alternatively, use functions like IMPORTHTML() and IMPORTXML() to automate updates, eliminating the need for manual copy-pasting.
Disclaimer: This tutorial serves educational purposes only. Dive into the world of web scraping responsibly and professionally.
Importing data from a 'table' or a 'list' within an HTML page:
Syntax: =IMPORTHTML(url, "query", index)
- url - The URL of the page to examine, including protocol (e.g. http://).
- The value for url must either be enclosed in quotation marks or be a reference to a cell containing the appropriate text.
- query - Either "list" or "table" depending on what type of structure contains the desired data.
- index - The index, starting at 1, which identifies which table or list as defined in the HTML source should be returned.
- The indices for lists and tables are maintained separately, so there may be both a list and a table with index 1 if both types of elements exist on the HTML page.
Usage :
=IMPORTHTML("https://en.wikipedia.org/wiki/Fortune_500" , "table", 1)
=IMPORTHTML(A1,B1,C1)
Example :
- Open a blank spreadsheet
- Type the function or you can copy paste the above code snippet in your spreadsheet it'll do the same thing. In this example I'm using the list of Top ten Fortune 500 companies from Wikipedia :
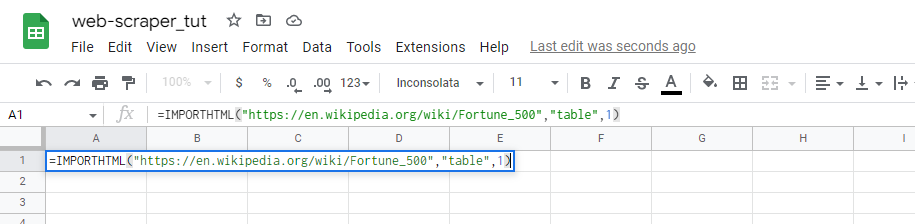
- You will see that only the first table scraped from the website because we choose Index 1 :
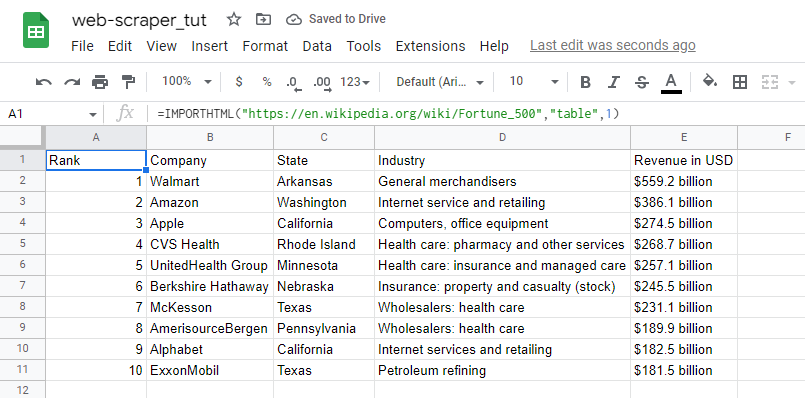
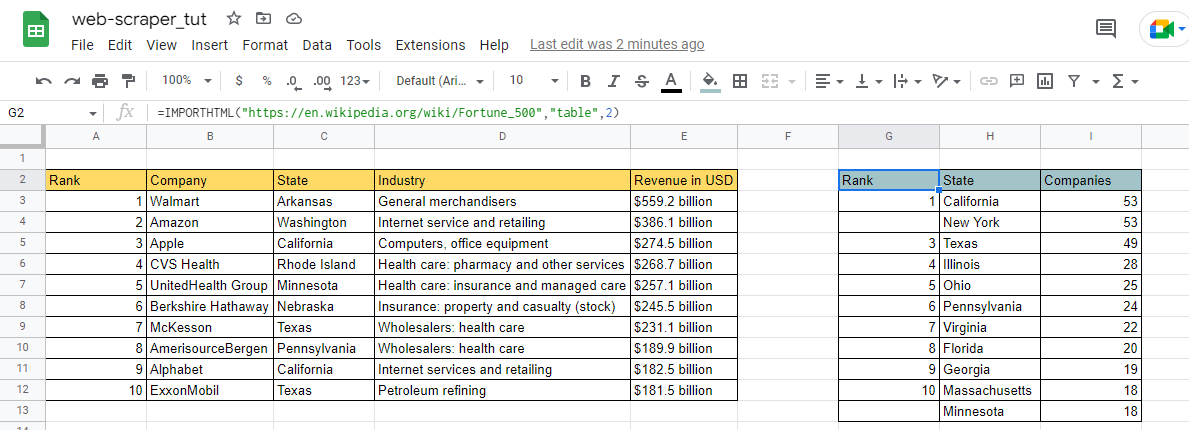
Let's scrape another table below (for fun) :
Here you'll see that I've used the Index 2, because I wanted to scrape the second table to my spreadsheet. I also added the borders and a light shade of color for headers to make it look fancy:
Importing data from various structured data types including XML, HTML, CSV, TSV, and RSS and ATOM XML feeds:
Syntax: =IMPORTXML(url, xpath_query)
- url - The URL of the page to examine, including protocol (e.g. http://).
- value for url must either be enclosed in quotation marks or be a reference to a cell containing the appropriate text.
- xpath_query - The string that instructs the function on the kind of data we are attempting to import. XPath query is used to work with structured data.
Usage :
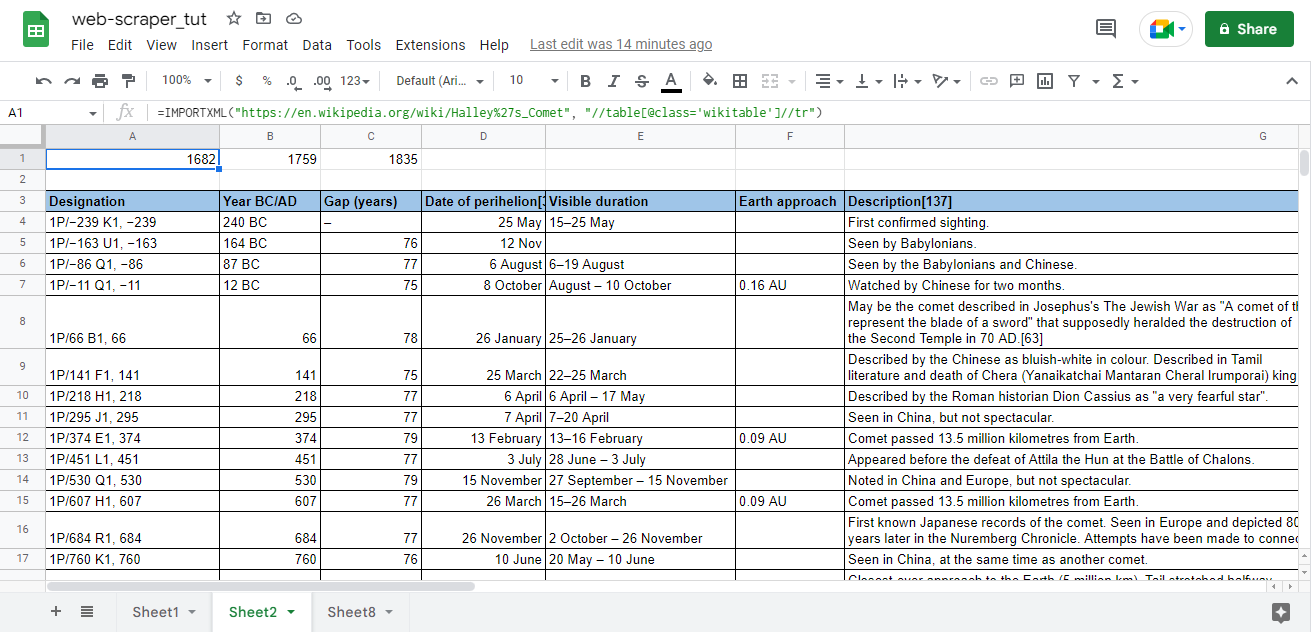
=IMPORTXML("https://en.wikipedia.org/wiki/Halley%27s_Comet", "//table[@class='wikitable']//tr")
=IMPORTXML(A2,B2)
Example :
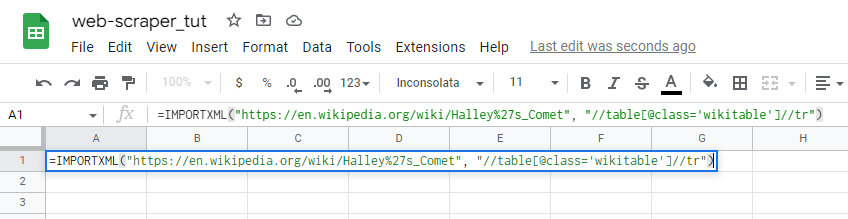
- Open a blank spreadsheet
- Type the function and the URL or you can paste the above code snippet in your spreadsheet if you're trying for the first time. In this example I'm using the sighting of Halley's Comet data :
You might have questions about what's going on with the xpath attribute and what the heck is table and class? Well, these are HTML elements. All I did here was to look for table tag in the HTML webpage and it's class because a single Website could have multiple table tags and even have multiple classes, if you want to be more specific you can use id instead of class when available.
Here's how you can look for the specific tags or elements from where you want to scrape your data :
- Right click on the website from where you want to scrape data, Press 'Inspect' or 'Inspect Element'.
A new window will pop in front of you with a lot of code, don't be scared because this is the fun part.
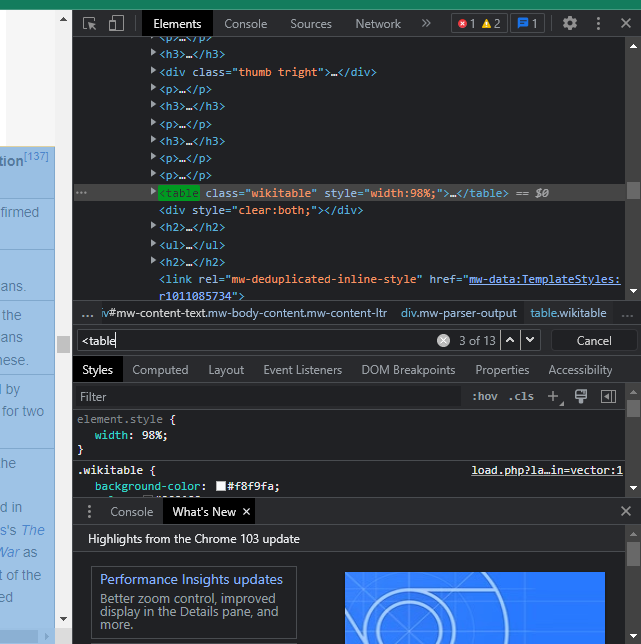
If you know even just a little bit about HTML tags and elements you can easily find the things you are looking for. In the above example I want to scrape all the data in the table and I know that in HTML there's a <table> tag for this purpose only. So I went straight for that by typing :
CTRL + F (This will open a search box)
In the search box, type the tag you want to search.
- When you hover your cursor over the Element, it'll highlight it's function in view pane on the left side (Chrome) so you can be sure that the tag you selected is correct.
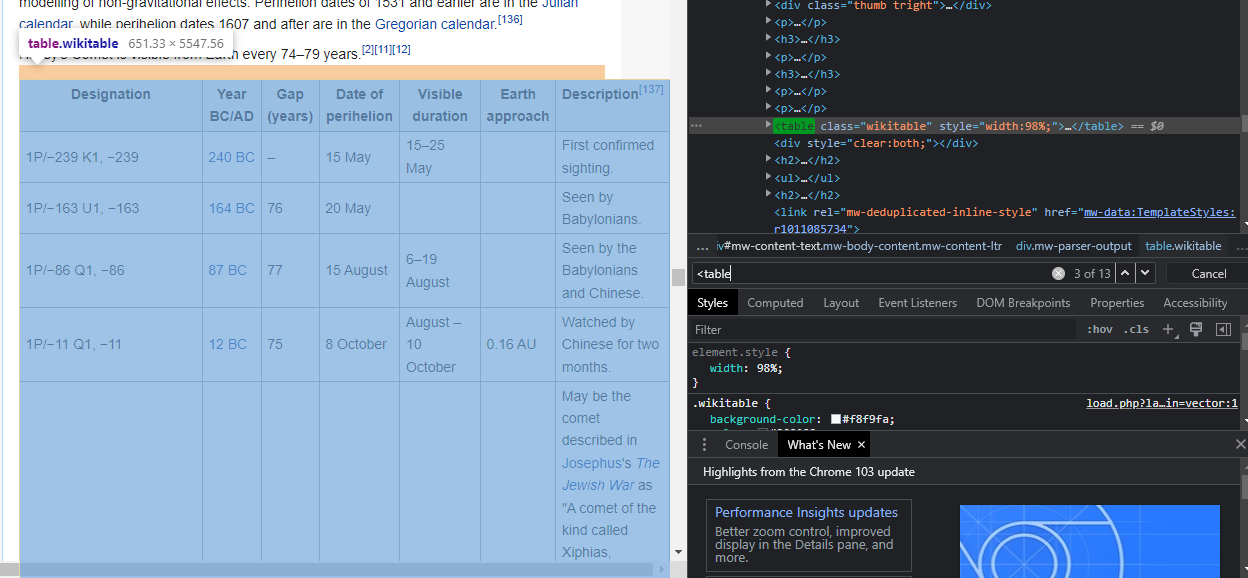
You can see the highlighted area in light blue shade.
If you want to learn more about xpath check out this article from w3schools, and for HTML tags and for Elements you should check this another article.
- The final result would be something like this (Again I've added borders and color for header) :
Here you go, this is all you need to scrape data from websites using Google Sheets. This might come really handy if you want to derive insights for your small project or if you want to learn about scraping in general but If you are someone who often have to scrape data, My suggestion would be to use programming language like Python. They are way more efficient. Just respect laws and others privacy.



